
Data Is (Always) Different

Inconveniently for database and software designers, input data is almost never organized the same way as their ad hoc schema. Furthermore, input data usually varies in format over time, as users decide to include more or fewer fields, when personnel changes or software updates cause confusion in data extract procedures, or when new systems are added to the input -- or for a host of other reasons.
A useful data analysis system must not only adapt itself to input data, but also adapt itself to changes in the input data over time. This requires the following:
- An easy way for users to "type" their data so that the system can catch and repair formatting errors
- An easy way for users to understand whether data have been loaded correctly
- An easy way for users to add data to the system when the data requires transformation because it may not match the format or semantics of previous data added to the system
Transforming input data
Consider the problem of input data that changes over time. Here is the typical issue, diagrammed out as solved by Spendata.
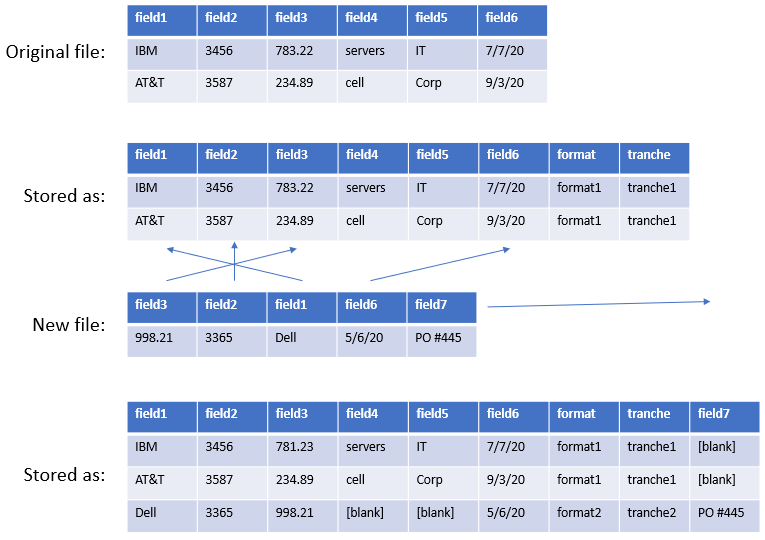
In the diagram above, Spendata created an input format ("format1") for the original file ("tranche1"). When a new file of a different format is loaded, the user is provided with a dialog that matches the new fields to the existing fields. The dialog provides for visual matching of fields as well as automatic matching by field name. If desired, the user appends new fields that are missing from the original format, and the system populates those new fields (missing in the original data) with blanks. Spendata then creates a new input format for these records ("format2") that can be used subsequently when new data appears in that format.
This functionality covers most of the cases commonly encountered. It does not, however, cover the case of data that requires more complex transformations before it can be merged with existing data. We discuss this in a subsequent post.