
Quick Win: Match Contracts to Spending
Matching contract information to spending data yields immediate benefits. Bypass spend becomes apparent. Missing contracts become obvious. And contract reviews can be appropriately prioritized.
However, the matching process can be difficult because normalizing and matching vendor names from disparate datasets isn’t easy. With Spendata, though, the process is not only easy, but almost entirely automatic.
For example, here are two sample data feeds — a list of vendor names and amounts from the AP system, and a list of the vendor contracts.

We can't match the data as is, because each system has its own idea of how to name Vendors, and the names don't match. With Spendata this is not a problem. We simply load both datasets and auto-family the vendor names, which normalizes them and groups like names under a single parent. We then link the two datasets on the parent names. At a glance we can see missing contracts:
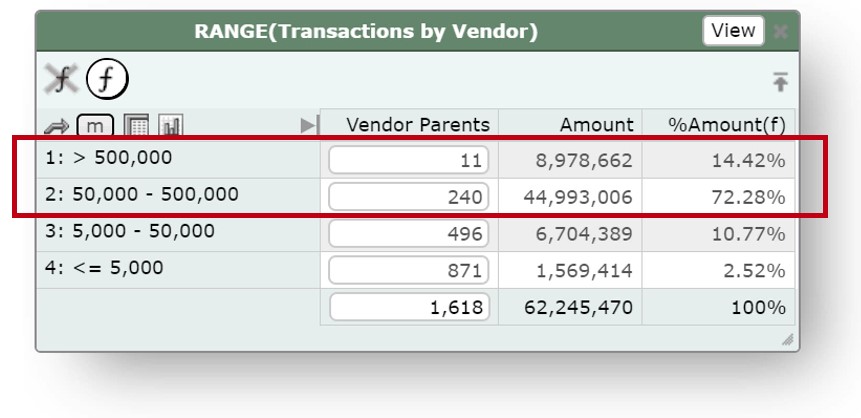
Clearly there are opportunities to set up contracts with large Vendors for whom there is no current contract.
We can also generate a comprehensive display of matching contracts — spending for which no contract is found, spending with matching contracts, and spending where no contract is expected.
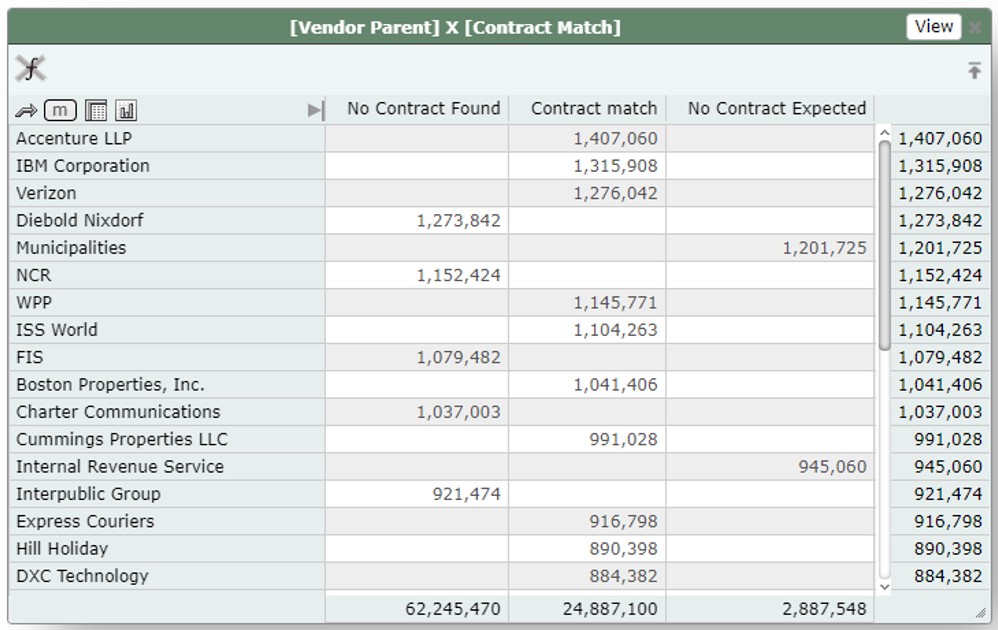
It's also easy to find discrepancies between the contracts information and the information from AP. This includes existing contracts for Vendors not found in AP spending:
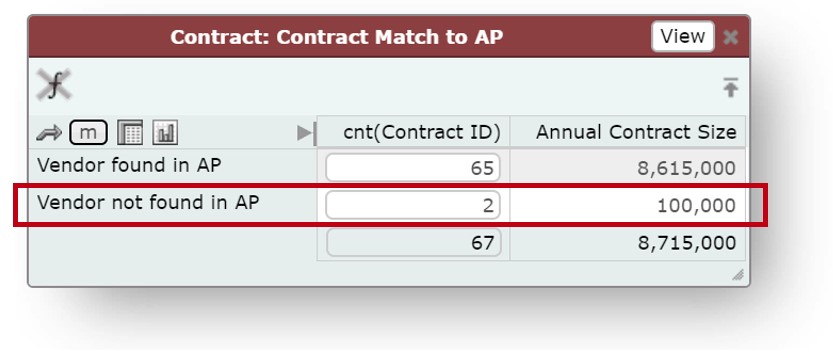
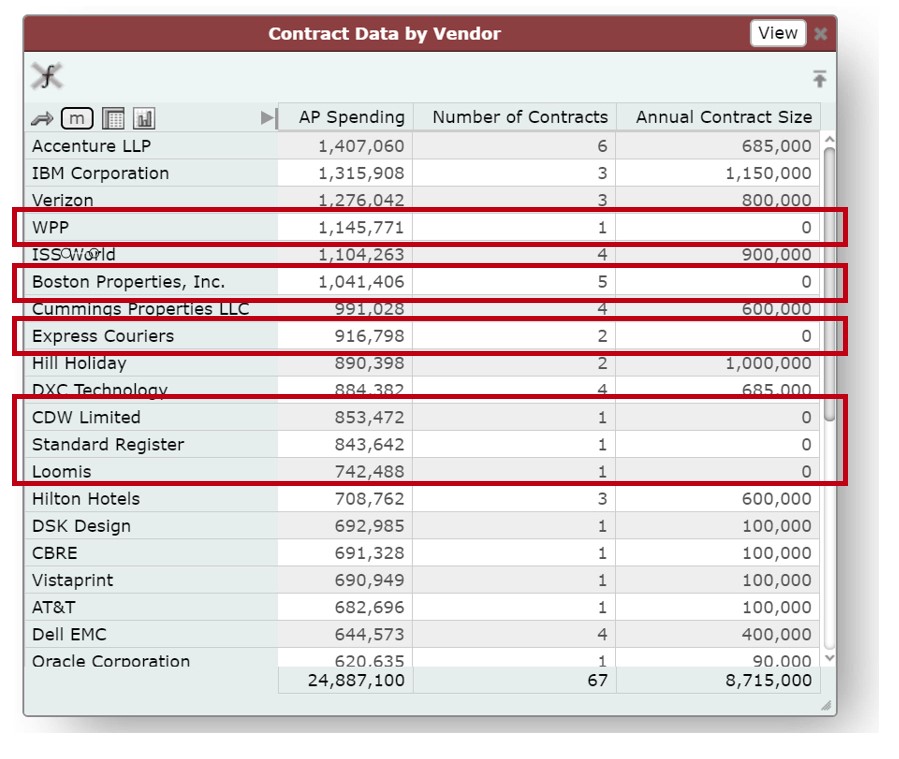
We can also find other discrepancies between the two datasets, such as spending in AP for contracts whose projected spending is zero. If we were to sort the contract data using the recorded contract size, we could easily either miss these highlighted vendors or accidentally delay action on them.
To summarize, merging contract data with spending data provides information previously unavailable. This allows Legal and Procurement to work together better by:
- Focusing on the largest relationships,
- Ensuring comprehensive coverage, and
- Eliminating oversights and mistakes.
With Spendata it’s easy.