
Databases Should Perform Like Spreadsheets
Analysts continue to rely on spreadsheets, to the despair of IT professionals and auditors. The latter rightly argue that the lack of rigor and auditability around spreadsheets promotes errors, prevents accountability, and in general lowers the quality of data analysis.
The reason analysts are “addicted to spreadsheets” is really quite simple. Spreadsheet models gain their power and popularity from dependencies – that is, the idea that a change in one area of a model will propagate through the model, causing a waterfall of changes to dependent areas. Consider this simple model:
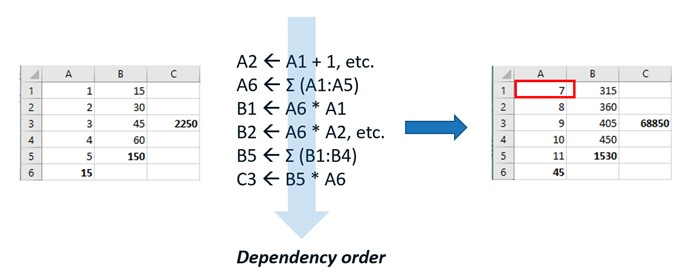
When we change cell A1 from “1” to “7”, column A is re-calculated, along with its sum in A6. Then column B is re-calculated based on the new values in A. Then the sum in B5 is re-calculated based on the new values in B. Finally, C3 is re-calculated as the product of A6 and B5. The author of this model can count on the dependencies being calculated in the proper order.
Databases can’t do this. Programs have to be written by data processing professionals to implement such dependencies and changing those programs requires still more programming. This awkwardness, slowness, and reliance on programmers and DBAs makes modeling inside a database a non-starter.
Spendata: A New Approach
Spendata solves this issue by design. Inside Spendata, dependencies are maintained automatically between data dimensions (columns), hierarchies, measures, data entry widgets, and rules. Just as with a spreadsheet, all of the above can be created in real time, then discarded or retained as the user wishes. Dimensions and measures can depend on other dimensions and measures. Rules can depend on dimensions, and dimensions can depend on rules. A single mapping change or data entry change will propagate through a Spendata model just like a spreadsheet. The dependencies can even span datasets. Here’s an example of Spendata dependencies:
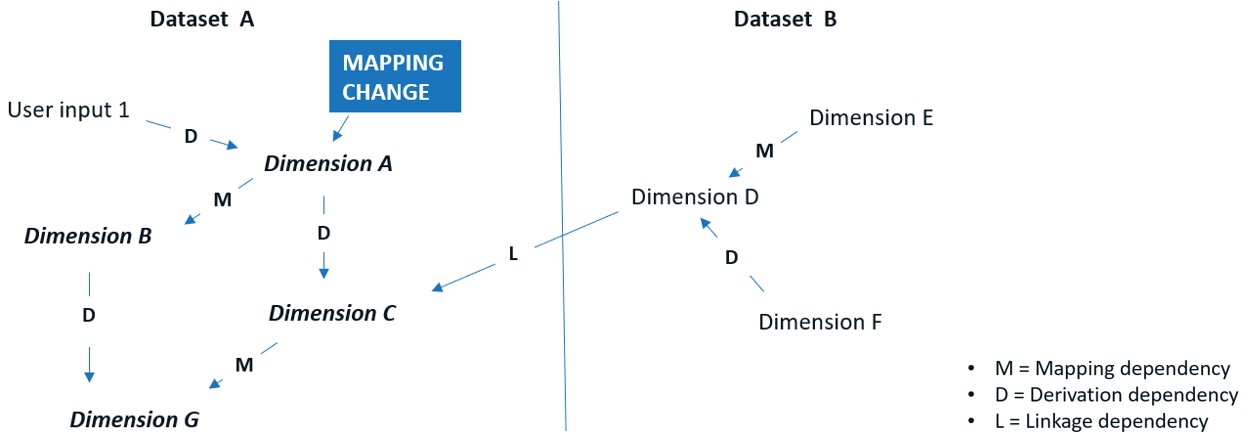
A change to a mapping rule in A causes an automatic cascade of effects: the re-mapping of B, the re-derivation of C, and the re-derivation and re-mapping of G.
Database as Spreadsheet
The consequences and advantages of maintaining dependencies between database elements are obvious. Analysts can build datasets in a controlled fashion, map them with rules that are both powerful and auditable, and create dynamic models that that can be vetted and are therefore trustworthy. Although Spendata can still export data to spreadsheets – and it can do so in a manner more efficient and powerful than most other tools – there is no requirement to do so. Analysis models can be built inside Spendata, typically much more efficiently and quickly.In brief:
- Spendata confers the ability to create dynamic models on millions of transactions, not just the few hundred thousand that Excel supports (Excel’s one million-row limit is largely fanciful; complex models of that size perform poorly, as analysts well know).
- The models created are built in a controlled environment, where data transformations are auditable, reversible, and repeatable.
- Building models is automatic, because dependencies are automatically maintained by the system. Change one item, and every dependent item is automatically rebuilt, just as in a spreadsheet.
- The nightmares associated with updating a spreadsheet when new data is added are gone. Spendata updates quickly and automatically, preserving all the dependencies and re-calculating everything that’s required.