
The Joy of Mapping: Modeling at Database Scale

A common issue in the spend analysis world — and the data analysis world as well — is a failure to appreciate the many uses and surprising power of data mapping. The idea of mapping is simple: given some selection criteria, force a column in the selected data to a particular value or label. In spend analysis, for example, the column might be "Commodity", the criterion might be "Vendor = Dell" and the label might be "PCs and Computing."
Mapping can be performed trivially in any relational database using an SQL query. A collection of such queries can "map" a column in the data as specifically as necessary.
Unfortunately, relational databases don’t provide answers quickly enough in environments with lots of transactions, so OLAP ("online analytical processing") technology is required to display and filter the mapped data. An OLAP database performs pre-calculations on the data so that answers can be provided rapidly. But since OLAP is based on pre-calculations, one can’t run around remapping its data, because then its answers will be incorrect. Before the system can respond with a new and correct answer, it has to redo its pre-calculations.
That means mapping becomes an offline process that must occur before pre-calculation. As a result, mapping has traditionally been viewed as separate from data display, and has been further limited to formalized processes around particular columns — in spend analysis, "Commodity".
Taking the Gloves Off
But what if mapping becomes an online process applicable to any column, rather than an offline process specifically for Commodity? In that case, "mapping" no longer means just "Commodity mapping" — any column can be mapped.
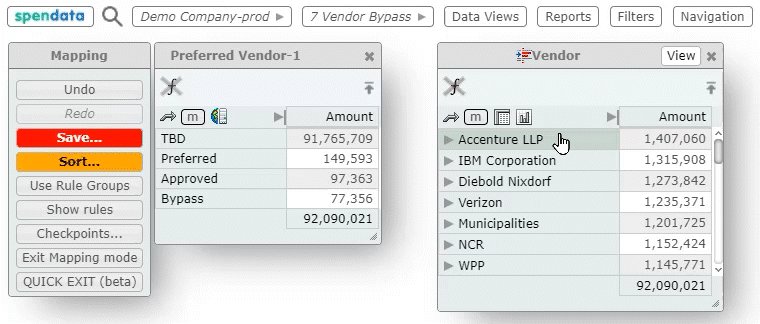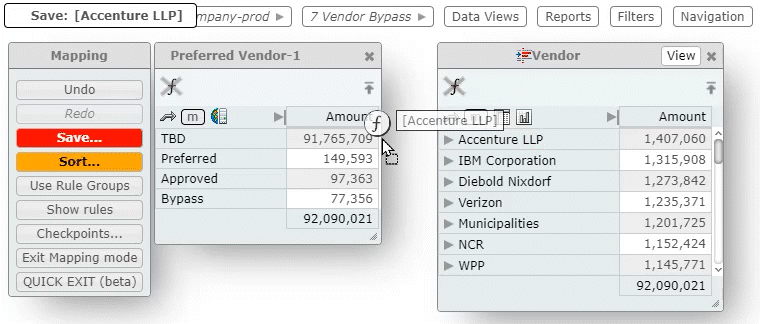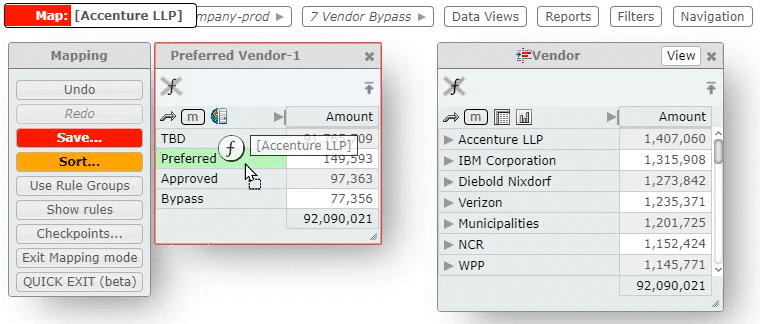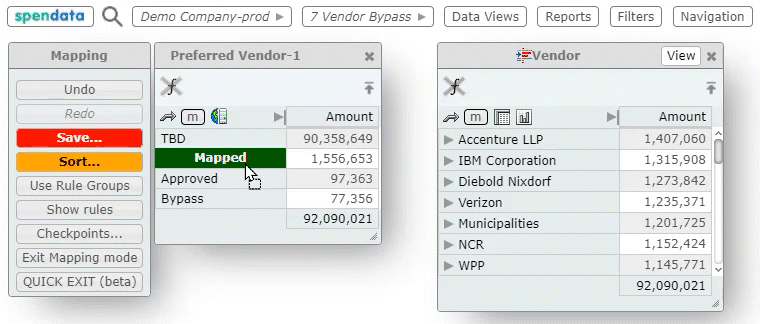
And if the mapping criteria for column A depends, in part, on column B — and if column B depends on mapped column C, and so on — then changing the mapping for a particular column can trigger a cascade of changes in the database.
It’s not only mapping dependencies that matter — it’s also derivation dependencies. Suppose that the very definition of column A depends on mapped column B. In that case, a change in the mapping of B will cause column A to be completely rebuilt.
To understand how powerful this idea can be, one need only look at spreadsheets, which gain all of their usefulness from the dependencies created between the calculations being specified.
The challenge with an OLAP database is to adjust its pre-calculations quickly enough to make online mapping possible and effective — and to maintain complex dependencies reliably so that displayed results are always accurate. Multiple types of dependencies must be maintained between columns, hierarchies, and inputs; across federated datasets; and with dimensional results looped back to Fact as additional dependencies (recursive segmentation).
This is what Spendata does — and it’s one of several reasons why it is capable of modeling at database scale.