
Spend Analysis: One Ring Doesn't Rule Them All

It's impossible to satisfy every consumer of spend data with a single, centrally-mapped, read-only spend cube. The reasons are many, but the most important one is this:
Different stakeholders have different analysis needs.
- The IT group might want to understand its total spend with a particular vendor. But a centralized spend cube cannot provide this information, because some purchases are made through distributors and others directly with the vendor. More data needs to be incorporated into the analysis, in this case invoice detail from the distributors.
- Facilities has contracted with a services vendor for janitorial work, security, and outdoor maintenance. But there is uncertainty as to whether the rates actually being charged are the negotiated rates. Invoice data and contracted rates from the vendor must be included in order to perform the analysis. This information isn't available from a centrally-maintained cube of accounting system data.
- A data analyst is charged with producing custom analyses for management. She is routinely asked for reports that segment the data differently than the dimensions chosen by the cube maintainters. She needs to take different cuts at geographies, to combine some mappings together and separate others. She is asked to build models that simulate the result of cost-cutting strategies. None of these things are possible using a centrally-managed spend cube. She cannot change or modify the centralized cube, so it is useless to her.
In order to accomplish any of the above analyses, there has historically been only one course of action: download transactions, add new data to them, and analyze them elsewhere – typically in Excel. That was an inadequate answer when spend analysis systems appeared over 20 years ago, and it's just as inadequate now.
The Problem With A Centralized Cube
Every analyst and department wants access to the latest transactional data posted to the accounting system. They will also want access to whatever enhancements are performed centrally that could save them work, such as familying Vendors and mapping AP spending to Commodity.
That is the idea behind a maintained and continually refreshed centralized cube.
The problem is, a centralized cube just isn't that useful on its own. Users will need to overlay on top of it their own perspectives on mapping, add new data to it, and create custom data dimensions, views, and reports. Those operations can't be done with a read-only spend cube, and they are very hard to do with ordinary databases and spreadsheets. That's why most productive analyses of spend data – which require all of the above additions to (and customizations of) the central cube – are so very difficult to perform. Since a centralized cube offers no ability to modify it – many spend analysis vendors publish to off-the-shelf read-only BI tools like Qlik or Tableau – the spend cube devolves into merely a source of slightly better data with no further intrinsic value or use.
A New Perspective: Centralized AND Customized
Analysts as well as business users need to be able to make changes to the cube to support whatever line of reasoning they may be following. One group may think of a vendor as a logistics company; another might consider them to be a fuel supplier. Both points of view are likely valid. Indeed, studies have shown that it is difficult for experienced commodity managers to agree on vendor classification, even under the best of circumstances with clear heads and no pressure.
And, different groups of users will have deeply different interests. The IT group has zero interest in Marketing vendors, and vice-versa; so why subject them to each other's noise? The resulting cube will be top-heavy and useless – and it won't satisfy either group in the end.
So why not let stakeholders modify the base cube as they see fit, and also allow them to accept base cube changes when they become available? That way they keep their hard-won custom analyses over time, while benefiting from the refreshed data in the base cube. That's what Spendata's unique inheritance capability makes possible. No more arguments about what should be mapped where, or what dimensions should be built, or what data should be added; instead each stakeholder can do whatever is best for their own purposes.
In the diagram below, we have a base cube that is being refreshed from AP, PO, and purchasing card feeds on a regular basis. A stakeholder group modifies the base cube with custom dimensions, datasets, mapping rules, and so on. On refresh, the base cube changes are automatically merged with the stakeholder's custom modifications. Spendata ensures that the base cube modifications do not undo any custom changes.
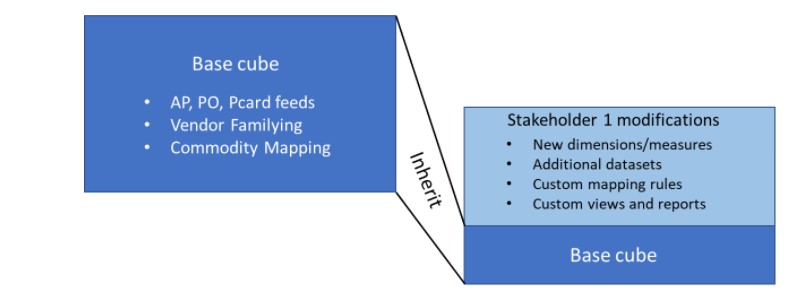
Obviously many stakeholder groups, including individual analysts, will set themselves up similarly:
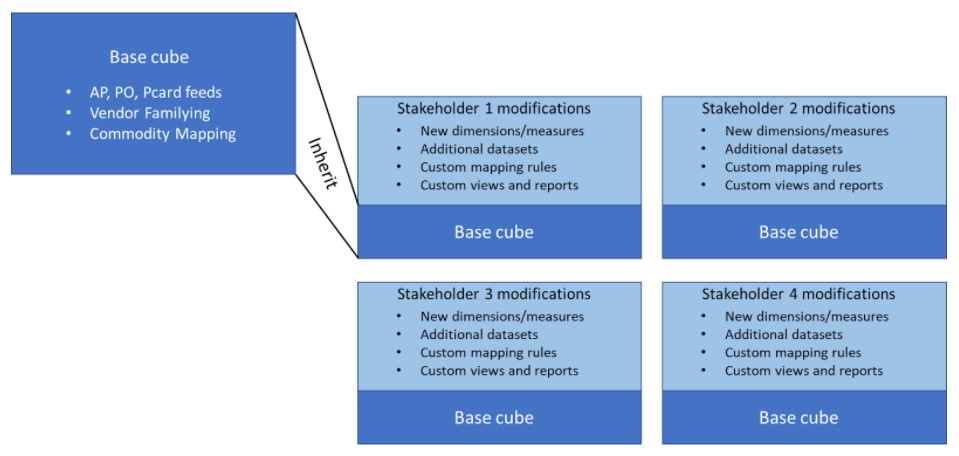
Because stakeholders can now modify and extend the cube to suit their needs, there is a shift in thinking from "How can I get data out of the cube so I can analyze it?" to "How can I use the cube to analyze my data?" The latter approach is dramatically better: answers and analyses come quickly, they're auditable, and they're repeatable and maintainable over time.
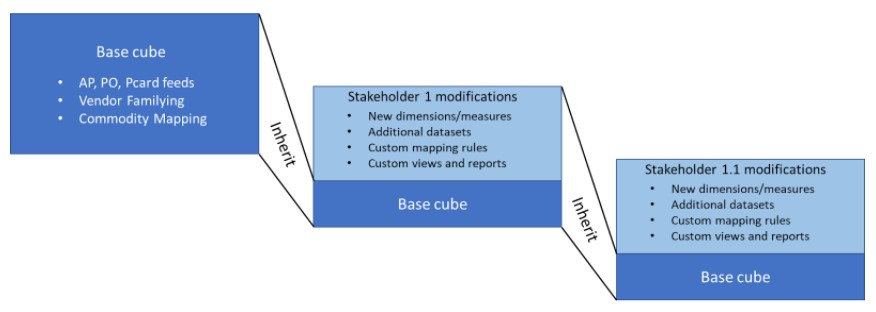
Of course, there is no reason why there should be only one level of inheritance – in fact, it is easy to see that there should be multiple levels. For example, individual IT analysts may have divergent needs for different purposes, so why shouldn't their starting point be the IT cube? In the diagram below, the cube marked "Stakeholder 1 modifications" becomes the "base cube" for the cube marked "Stakeholder 1.1 modifications" – and so on. Each inherits from its parent.
Summing Up
Who among us possesses the hubris to imagine that s/he could organize and map an analysis cube suitable for every consumer? It's flatly impossible, of course.
And what do we mean by "analysis"? Drilling around prefabricated dimensions of a fixed schema in a read-only BI tool? That's not analysis, and it's why real analysts are forced to download spend data to Excel or other third-party products to get real value from it.
But if a stakeholder cube can be built by modifying the base cube – benefitting from all the upstream refreshes and classification changes that have been made – with analyses being constructed and models being built right in the cube and preserved across refreshes – then that's a game-changer.
That's what Spendata brings to the party.